
12 Juin 2026
Azure AI Foundry est la plateforme unifiée de Microsoft pour créer, déployer et gérer des applications et agents d'IA en entreprise. Elle rassemble ce qui était auparavant éparpillé entre plusieurs services Azure, tels qu'Azure OpenAI, Azure Machine Learning et Azure AI Services. L'idée est simple : au lieu de naviguer entre plusieurs portails et services distincts, tout se gère depuis un seul hub, le portail Microsoft Foundry.
Dans cet article on va voir ensemble l'ensemble des services et les modèles qu'Azure AI Foundry propose.
C'est l'unité organisationnelle de base de la plateforme.
Le Hub est le conteneur le plus important. Il regroupe les ressources partagées entre plusieurs équipes, comme les connexions aux services Azure, les configurations réseau, les politiques de sécurité et l'accès aux modèles. Une équipe centrale IT ou MLOps crée et gère généralement un Hub.
Un Hub peut héberger des dizaines de projets avec des accès et des politiques distincts.
Le Projet est l'espace de travail d'une équipe ou d'une application spécifique. Il hérite des ressources du Hub, mais il a son propre espace isolé pour les expérimentations, les déploiements et les évaluations. C'est ici que les développeurs travaillent chaque jour.
C'est la bibliothèque centrale de tous les modèles disponibles sur la plateforme. On y trouve trois grandes catégories :
La famille GPT, qui comprend GPT-5, GPT-4o, o1, o3, et ainsi de suite. Il y a aussi les modèles de génération d'images comme GPT-image-1 et DALL-E. En plus, il y a les modèles audio et vidéo, comme Whisper et Sora. Et enfin, les modèles d'embeddings. Tous ces modèles sont hébergés par Microsoft sur leur infrastructure Azure.
Meta Llama 3, Mistral, DeepSeek-R1, Phi (la famille de petits modèles de Microsoft), Cohere Command R+, et bien d'autres. Ils sont accessibles en deux modes :
MaaS (Model as a Service) — une API serverless sans gestion d'infrastructure, facturation à l'usage.
MaaP (Model as a Platform) — le modèle tourne sur une instance de calcul dédiée, pour plus de contrôle.
Des modèles spécialisés proposés par des éditeurs via la marketplace Azure. Chaque modèle dispose d'une fiche détaillée : capacités, limitations, cas d'usage recommandés, benchmarks et mode de tarification.
Sélectionner un modèle dans le catalogue ne suffit pas. Il est nécessaire de le déployer pour pouvoir appeler le modèle via une interface de programmation d'applications. Azure AI Foundry propose plusieurs types de déploiements.
Le modèle est partagé entre plusieurs utilisateurs (Tenants), ce qui signifie qu'il est mutualisé. La tarification se fait en fonction de l'utilisation réelle, au moyen de tokens. C'est une solution particulièrement adaptée aux charges de travail variables ou aux différentes phases de développement.
De la capacité de calcul réservée exclusivement pour votre organisation. Latence prévisible, débit garanti. Recommandé pour les applications de production à fort trafic.
Pour les modèles open source, une endpoint d'API est créée sans avoir besoin de gérer une instance de calcul. La facturation se fait en fonction de votre consommation.
Chaque déploiement crée un endpoint (URL) et une clé API. Celle-ci est compatible avec l'authentification Entra ID. Les applications utilisent ces informations pour consommer les services.
C'est le moteur d'exécution des agents IA. Un agent est une entité autonome. Cette entité combine un modèle de langage, des instructions système, des outils et un accès à des sources de connaissances. Elle utilise ces éléments pour accomplir des tâches complexes.
Voici les éléments qui définissent le fonctionnement d'un agent :
Instructions système : Ce sont les règles qui déterminent comment l'agent doit se comporter, quel est son rôle et quelles sont les limites qu'il ne doit pas dépasser.
Modèle sous-jacent : C'est le modèle de langage utilisé par l'agent pour prendre des décisions, comme par exemple GPT-4o ou Mistral.
Outils : Il s'agit des actions que l'agent est capable d'exécuter, comme effectuer des appels d'API, rechercher des informations dans des fichiers ou exécuter du code.
Threads : Chaque conversation avec l'agent est appelée un thread, et chaque thread conserve un historique de tous les échanges et l'état actuel de l'agent.
Runs : Chaque fois que l'agent est déclenché sur un thread, cela s'appelle un "run", et c'est l'unité de base pour l'exécution de l'agent.
Recherche dans des fichiers : l'agent peut effectuer une recherche dans des fichiers uploadés tels que des documents PDF ou Word. Cette recherche est possible grâce à une base vectorielle qui est créée automatiquement.
Interpréteur de code : l'agent est capable d'écrire et d'exécuter du code Python dans un environnement sécurisé appelé sandbox. Cela lui permet d'analyser des données et de générer des graphiques.
Bing Grounding : l'agent utilise l'API Bing Search pour ancrer ses réponses sur le web en temps réel.
Azure AI Search : l'agent est connecté à un index de recherche pour le RAG, ce qui lui permet de rechercher des informations dans des données d'entreprise.
Logic Apps : l'agent peut déclencher des actions dans diverses applications telles que Salesforce, SAP, ServiceNow et SharePoint, grâce à plus de 1 400 connecteurs.
Fonctions personnalisées : il est possible de définir vos propres outils que l'agent peut appeler selon le contexte.
Au-delà d'un seul agent, Azure AI Foundry permet de gérer plusieurs agents qui travaillent ensemble. Chaque agent a une spécialité, et un agent coordinateur dirige leur travail. Des outils comme AutoGen ou Semantic Kernel peuvent aussi aider à organiser cette collaboration.
A2A (Agent-to-Agent) : Protocole standardisé pour la communication directe entre agents, y compris des agents hébergés sur d'autres clouds.
MCP (Model Context Protocol) : Intègre n'importe quel outil ou backend via des appels JSON-RPC standardisés, sans spécification OpenAPI custom.
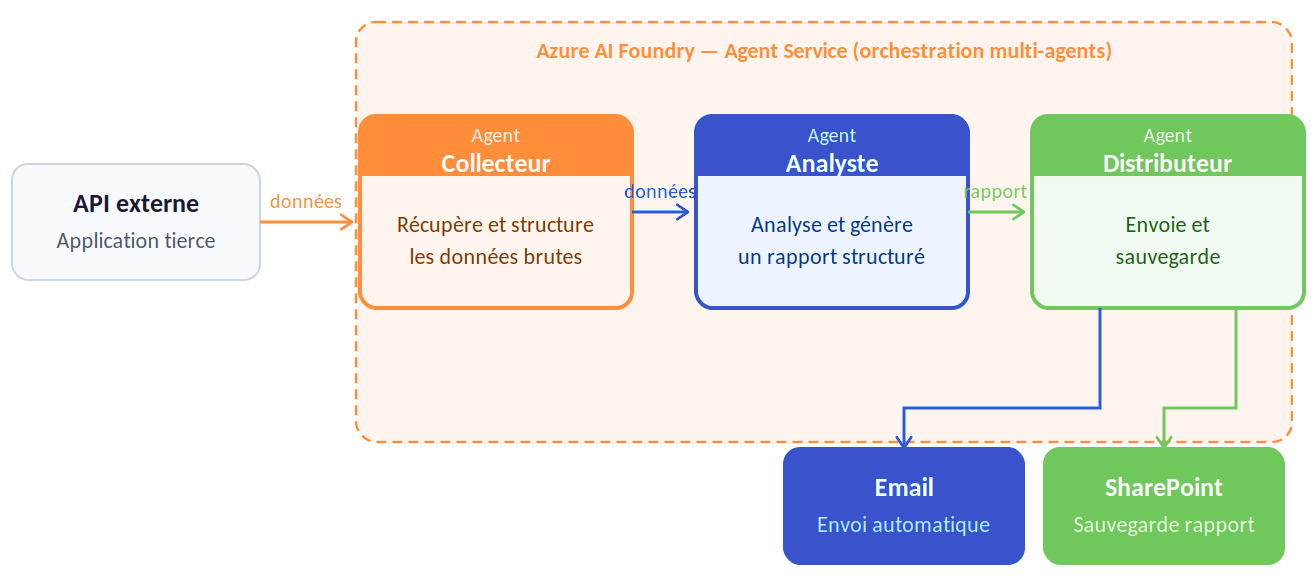
Un agent collecteur récupère des données depuis une application programmable externe. Cet agent collecteur transmet ensuite ces données à un agent analyste. L'agent analyste utilise ces données pour générer un rapport. Ensuite, un agent distributeur prend ce rapport et l'envoie par courrier électronique. Enfin, l'agent distributeur sauvegarde le rapport dans SharePoint. Tout cela se fait sans qu'il soit nécessaire d'avoir recours à une intervention humaine.
Le RAG (Retrieval-Augmented Generation) est le mécanisme qui permet à un agent de répondre à partir de vos propres données plutôt que de son seul entraînement.
Le service central pour le RAG dans Foundry est très utile. Il permet de créer des index hybrides, ce qui signifie qu'il combine la recherche par mots-clés et la recherche vectorielle sémantique. Cela offre une précision de récupération nettement supérieure à une recherche classique. Le RAG dans Foundry est donc très efficace pour trouver ce dont vous avez besoin.
Azure Blob Storage, Azure Data Lake
SharePoint Online et OneDrive
Microsoft Fabric (données structurées et analytiques)
Bases de données SQL Azure
Bing (données web en temps réel)
Ce service complémentaire permet d'extraire du sens à partir de documents multimodaux tels que des PDF, des images, des vidéos et des formulaires. Son but est de préparer ces documents pour l'indexation. Pour cela, il utilise plusieurs outils tels que la reconnaissance optique de caractères, l'extraction de tableaux et la segmentation de contenu. Ce service est configurable de manière très simple, car il peut être réglé via un espace de test sans code, directement dans le portail Foundry.
Quand un modèle généraliste ne suffit pas, Azure AI Foundry offre plusieurs niveaux de personnalisation :
Entraînez le modèle avec vos propres données, comme des paires question/réponse ou des exemples de conversations. Le modèle va apprendre le style, le vocabulaire et les comportements spécifiques à votre domaine.
Pas d'entraînement, mais injection de contexte à chaque requête. Plus agile que le fine-tuning, adapté aux données qui changent fréquemment.
Un grand modèle, appelé "enseignant", est utilisé pour générer des données synthétiques de haute qualité. Ces données servent ensuite à entraîner un modèle plus petit, appelé "élève". L'objectif est d'obtenir un modèle léger, ce dernier est performant pour une tâche spécifique. De plus, il a un coût d'inférence réduit.
Fonctionnalité essentielle pour une mise en production responsable, le module d'évaluation permet de mesurer objectivement la qualité des réponses de vos modèles et agents.
Groundedness : L'agent répond-il à partir des faits fournis, ou hallucine-t-il ?
Relevance : La réponse est-elle pertinente par rapport à la question ?
Coherence : Le texte généré est-il cohérent et logique ?
Fluency : La qualité linguistique du texte produit.
Similarity : Comparaison avec des réponses de référence (ground truth).
Ces évaluations peuvent être lancées manuellement sur un jeu de données test. Elles peuvent également être intégrées dans un pipeline CI/CD. Cela permet de valider chaque nouvelle version d'un agent avant de le déployer en production.
Des filtres configurables bloquent les contenus nuisibles dans les entrées et les sorties : violence, haine, contenu sexuel, données personnelles, etc. Chaque catégorie dispose d'un seuil ajustable selon les besoins de l'application.
La protection est conçue pour empêcher deux types d'attaques. Elle protège contre les injections directes. C'est-à-dire qu'un utilisateur tente de détourner le comportement de l'agent via son prompt. Elle protège également contre les injections indirectes. C'est-à-dire qu'un document malveillant est uploadé et qu'il contient des instructions cachées.
Détecte en temps réel si une réponse est ancrée dans les sources fournies ou s'il s'agit d'une hallucination.
Un seul système de contrôle d'accès basé sur les rôles pour tous les composants : qui peut déployer un modèle, créer un agent, consulter les logs, etc.
Les politiques de conformité de votre organisation (régions autorisées, types de modèles permis, exigences réseau) s'appliquent automatiquement à toutes les ressources Foundry.
Prise en charge des VNet, Private Endpoints et des configurations réseau isolées pour les environnements hautement sécurisés.
Collecte des métriques d'utilisation : nombre de requêtes, latence, tokens consommés, taux d'erreur.
Chaque run d'un agent génère une trace détaillée : quels outils ont été appelés, dans quel ordre, avec quels paramètres, combien de temps chaque étape a pris. Indispensable pour le débogage.
Les traces sont exportables vers n'importe quel système d'observabilité compatible : Jaeger, Datadog, Application Insights, etc.
L'interface web centrale est un espace où vous pouvez tester les modèles. C'est un peu comme un terrain de jeu. Il y a également un outil de création visuelle pour les agents. Vous pouvez utiliser l'interface de déploiement pour mettre en ligne vos modèles. De plus, il y a des tableaux de bord pour évaluer et surveiller les performances.
Disponible en Python, JavaScript, Java et C#. Fournit un contrat d'API cohérent pour interagir avec tous les services Foundry sans changer de client selon le fournisseur de modèle.
Vous pouvez explorer le catalogue de modèles, créer et déployer des agents, et profiter de l'IntelliSense YAML pour les configurations d'agents, tout en restant dans l'éditeur.
Interface en ligne de commande pour l'automatisation et les pipelines CI/CD DevOps.
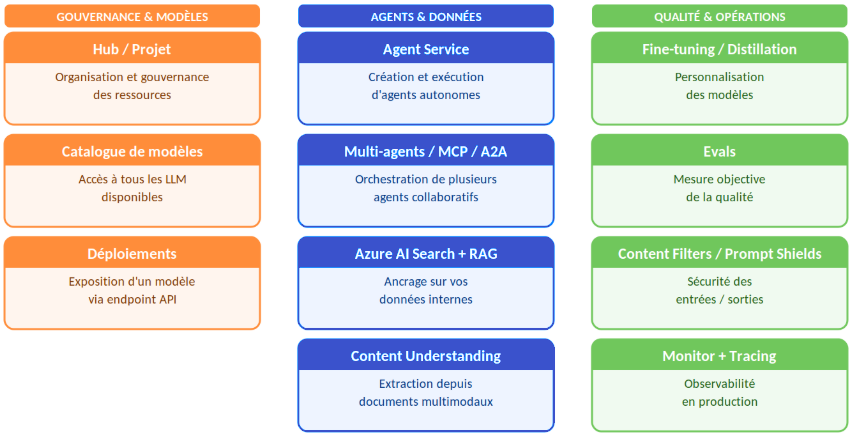
Azure AI Foundry est bien plus qu'un simple accès à model IA sur Azure. C'est en réalité une plateforme MLOps très complète qui prend en charge toutes les étapes de la vie d'une application d'intelligence artificielle. Elle permet l'exploration, le développement, l'évaluation, le déploiement, le suivi et la gouvernance. Tous ces éléments sont réunis au sein d'un environnement unifié et sécurisé.